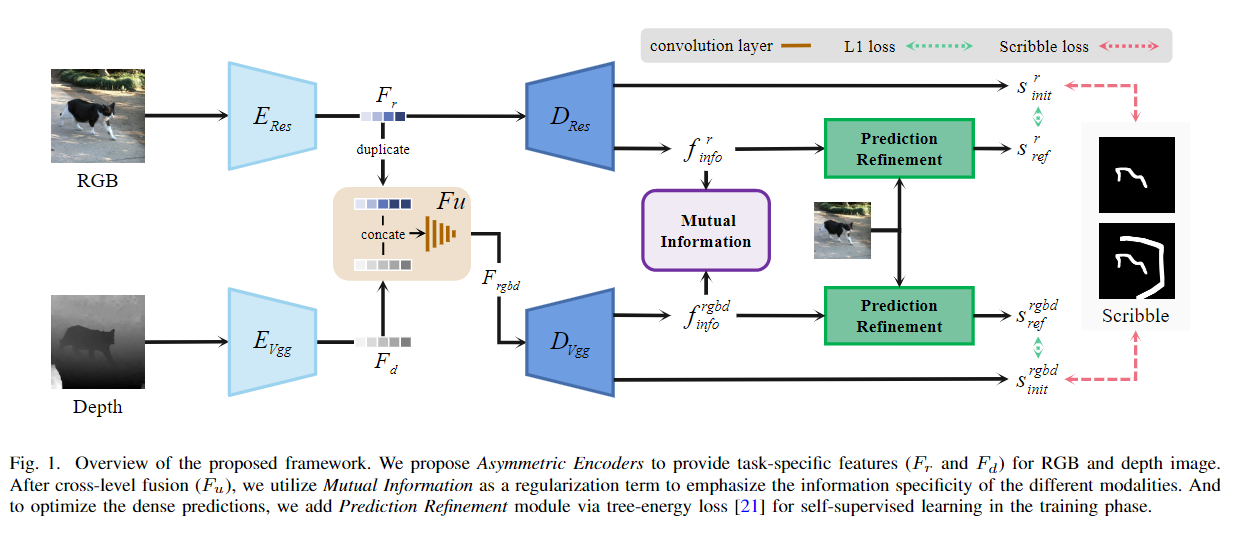
Contributions
(1) We introduce a mutual information optimization method to explicitly model the contribution of RGB and depth for weakly-supervised RGB-D saliency detection;
(2) We present asymmetric feature extractors, taking advantage of different backbones' encoding abilities to achieve more reliable feature representation;
(3) We present a multimodal variational auto-encoder framework as the second stage refinement solution to refine model prediction, which is proven more robust to error propagation issues caused by pseudo labeling.
Network Architecture
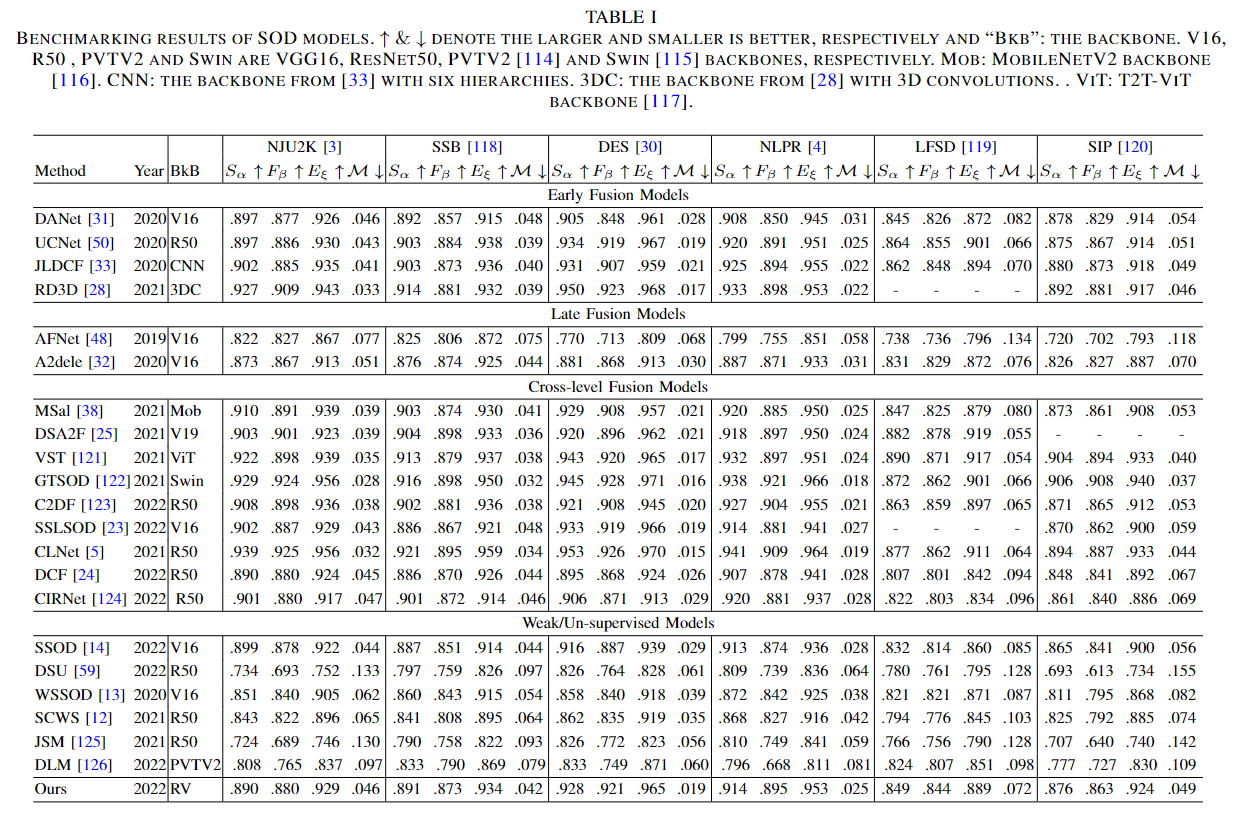
Benchmarking results of SOD models.
Visualization of the generated saliency maps from benchmark RGB-D saliency detection models and ours.

Citation
@article{li2023mutual,
title={Mutual Information Regularization for Weakly-supervised RGB-D Salient Object Detection},
author={Aixuan Li and Yuxin Mao and Jing Zhang and Yuchao Dai},
booktitle = {IEEE Transactions on Circuits and Systems for Video Technology},
year={2023}
}