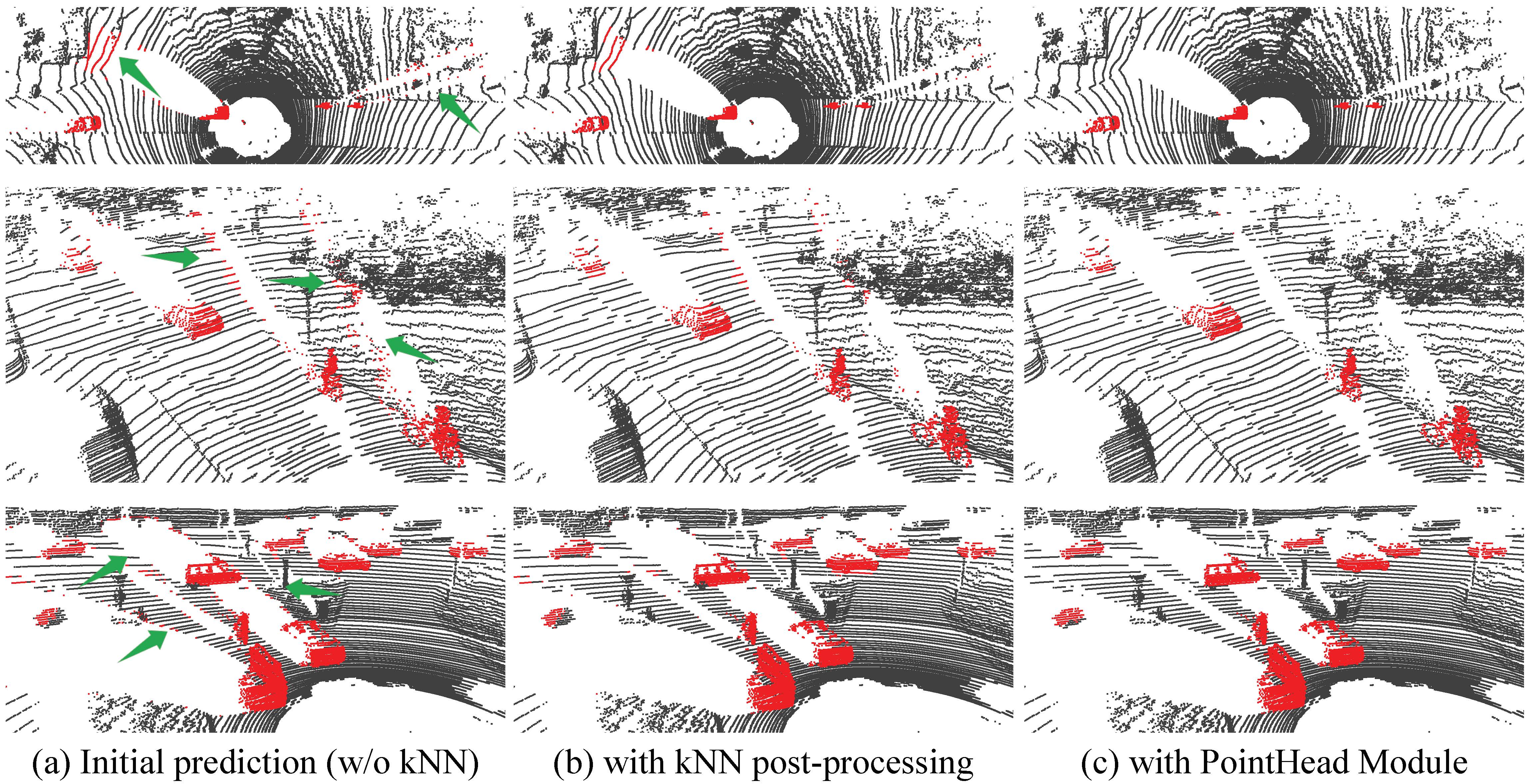
MotionSeg3D Architecture
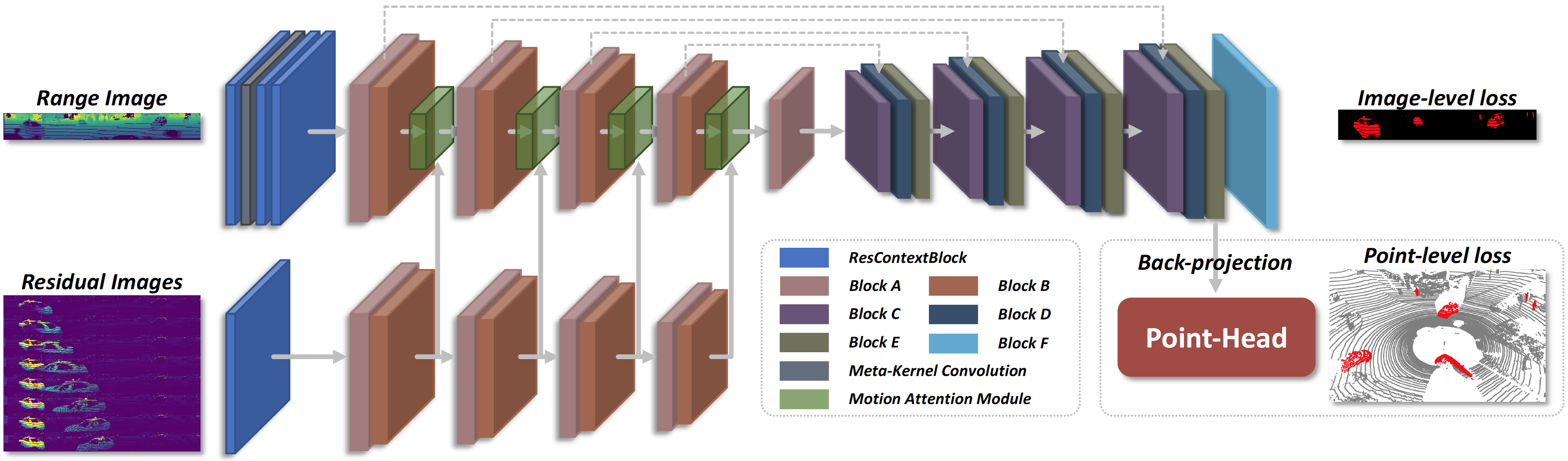
Overview of our method. We extend and modify SalsaNext into a dual-branch and dual-head architecture, consisting of a range image branch (Enc-A) to encode the appearance feature, a residual image branch (Enc-M) to encode the temporal motion information, and use multi-scales motion guided attention module to fuse them. And then an image head with skip connections is used to decode the features from fronts. Finally, we back-project 2D features to 3D points and use a point head to further refine the segmentation results. Specifically, BlockA and BlockE are the ResBlocks with dilated convolution, BlockB is the pooling and optional dropout layer, BlockC is the PixelShuffle and optional dropout layer, BlockD is the skip connection with optional dropout, BlockF is the fully connected layer.