Motivation
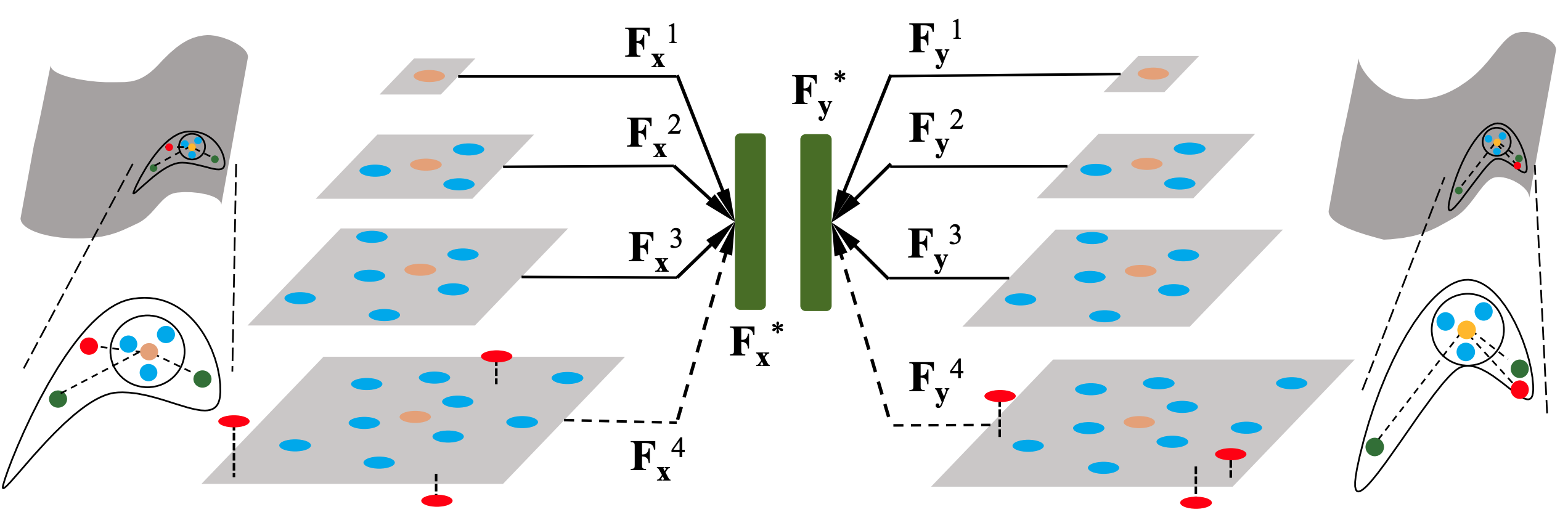
Motivation of our proposed dynamic fusion strategy. There is an inevitable struggle between robustness and discriminativeness of single scale feature description. Due to repetitive minor structures, the small scale descriptors are not discriminative enough but are robust due to little interference. By contrast, the large receptive field improves the discriminativeness of large scale feature, which is easy to be affected by many disturbers. Existing multi-scale fusion methods usually utilize each scale equally, which cannot improve the robustness as the disturbers are also encoded to the final descriptor. Thus, we design a dynamic fusion module, which recognizes and selects consistent and clean ones dynamically during the fusion. By focusing on multiple clean scale features, it achieves a good balance between discriminativeness and robustness. Here, we provide a toy example, where yellow denotes the current point (i.e. $x$, $y$) and red is noise, gray parallelograms indicate different receptive fields. Obviously, the features of the first 3 scales $F^1_x$, $F^2_x$, $F^3_x$ and $F^1_y$, $F^2_y$, $F^3_y$ are consistent in describing similar local geometry (a plane). However, the last scale features $F^4_x$ and $F^4_y$ show deviation due to the noise and deformation. Our designed dynamic fusion module enforces the final feature $F^∗_x$, $F^∗_y$ approach to the first 3 scale features while marginalizing the last scale feature.