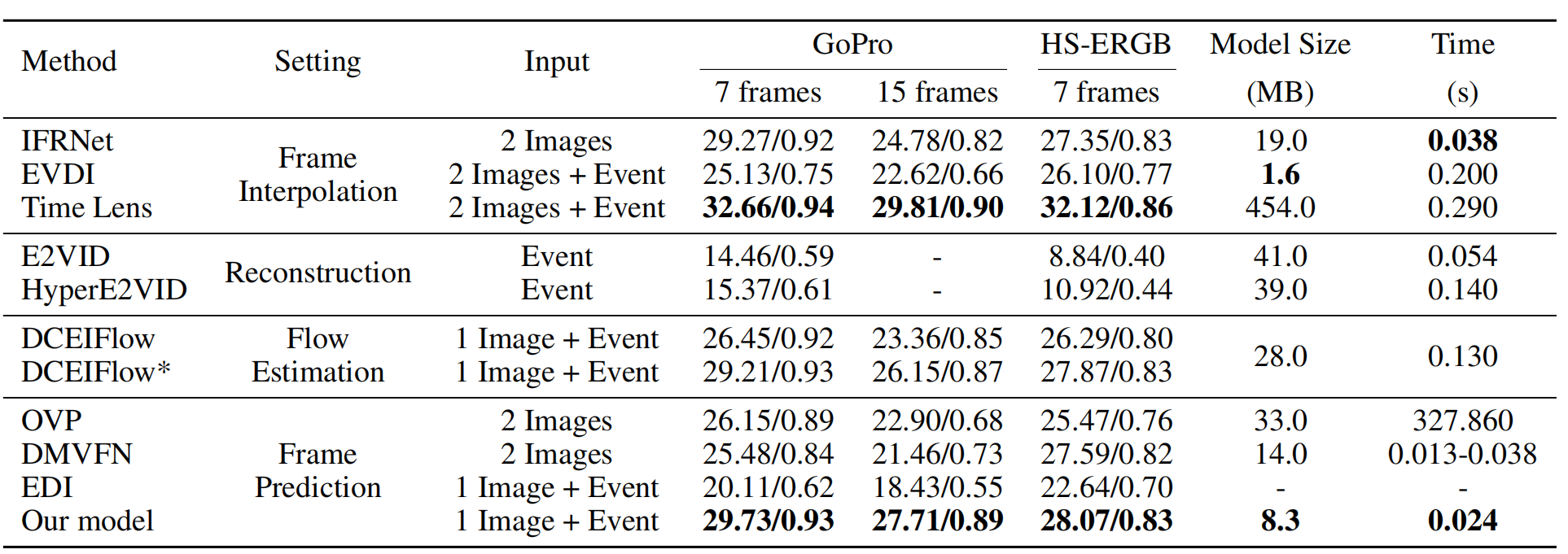
Model Architecture
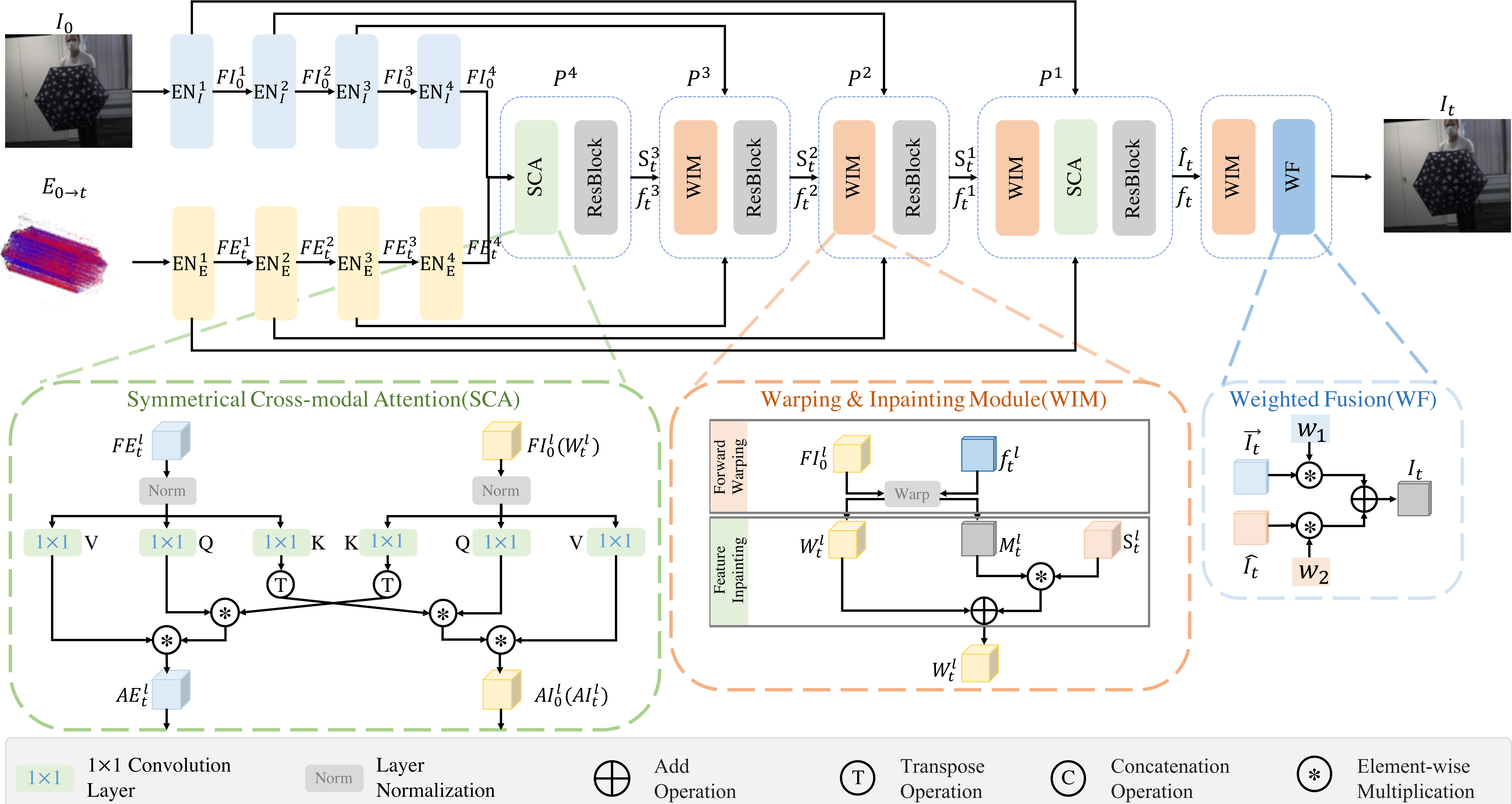
In our framework, we first use two encoders to extract pyramid features for the image and events. Then we apply a coarse-to-fine joint decoder to get the synthesized feature and optical flow at each pyramid layer. In the decoder, we utilize Symmetrical Cross-modal Attention(SCA) to augment both image and event features. We also introduce Warping and Inpainting Module(WIM) to repair the holes caused by forward warping and get spatially-aligned image features. Finally, we adopt Weighted Fusion(WF) to output the final frame prediction from the synthesized and warped frames.